
Mathematics, 19.03.2020 03:03 Brittpaulina
In these cases, we might try to correct for noise while training the classifier. Consider the following formulation for training a logistic regression classifier w ∈ R d on a noisy training data set (x (1), y(1)), . . . ,(x (n) , y(n) ), where for each i, y (i) ∈ {−1, +1}. For simplicity, we ignore the bias term b. Suppose we know that the noise magnitude is at most r. Then, instead of the standard logistic regression loss, we might want to minimize the following loss: L˜(w) = Pn i=1 L˜ i(w), where, L˜ i(w) = max z (i):kz (i)−x(i)k≤r log(1 + exp(−y (i)w >z (i) )), where kvk means the L2-norm of vector v. (a) (5 points) Prove that for all i, L˜ i(w) = Mi(w), where Mi(w) = log(1 + exp(rkwk − y (i)w >x (i) )). For full credit, show all the steps in your proof.

Answers: 2


Other questions on the subject: Mathematics
Mathematics, 21.06.2019 18:00, kaykardash
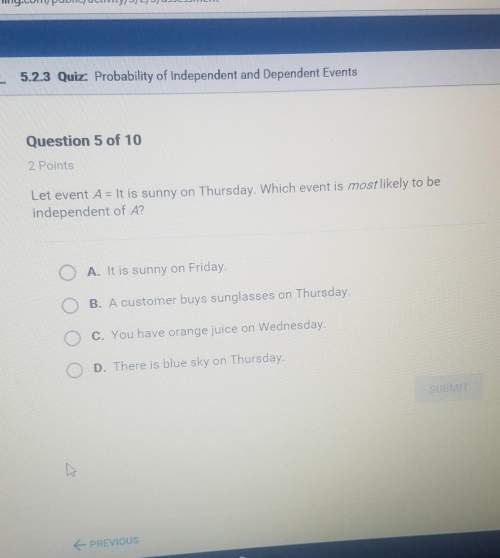
An appliance store sells lamps at $95.00 for two. a department store sells similar lamps at 5 for $250.00. which store sells at a better rate
Answers: 1
Mathematics, 22.06.2019 00:30, brainist71
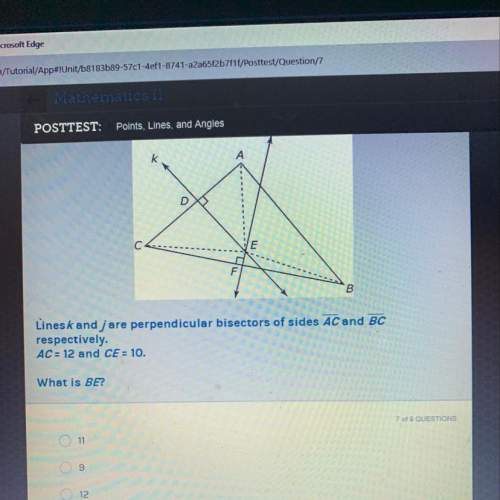
L|| m if m? 1=125 and m? 7=50 then m? 5= 5 55 75 105 next question ask for turn it in © 2014 glynlyon, inc. all rights reserved. terms of use
Answers: 3
You know the right answer?
In these cases, we might try to correct for noise while training the classifier. Consider the follow...
Questions in other subjects:


Arts, 22.07.2019 05:30

History, 22.07.2019 05:30

Mathematics, 22.07.2019 05:30


